句法分析Ⅰ
本文最后更新于 2026年6月14日 下午
北京大学信息科学技术学院 自然语言处理基础(2026春)的课程笔记
第九讲:Syntactic Analysis
句法结构
为什么需要句法分析?
语言不仅仅是词的序列,还遵循隐性的语法规则
相同的词序列可能因结构不同而有不同含义:
Jane ate spaghetti with fork(用叉子吃)
Jane ate spaghetti with meatballs(吃肉丸意大利面)
句法分析可以揭示这种结构差异。
组成成分(Constituent)
一组词可以作为一个整体单元(如名词短语NP、动词短语VP)
判断是否为成分的方法:
是否能出现在特定位置(如NP常出现在动词前)
是否能整体移动
是否能与其他成分并列
例子:Harry the Horse、a high-class spot 等都是NP
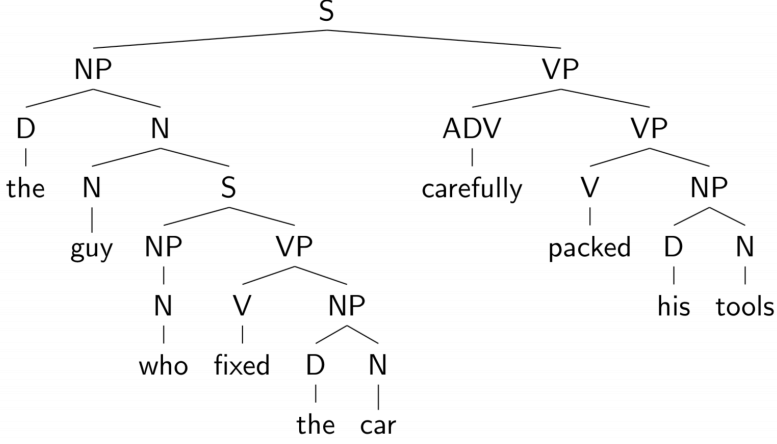
短语结构树(Phrase Structure Tree)
将句子组织为嵌套结构,形成树状图
语法与解析
上下文无关文法(CFG)
形式化定义:
终结符(单词)
非终结符(如NP、VP)
起始符号 S
产生式规则:A → β
例子:
S → NP VP
NP → Det N
VP → V NP
乔姆斯基范式(CNF)
每条规则必须是:
A → B C(两个非终结符)
A → w(一个终结符)
任何CFG都可以转换为CNF,便于解析
概率上下文无关文法(PCFG)
为每条产生规则$A_i \rightarrow \beta_i$分配一个概率$$q(A_i \rightarrow \beta_i)$$
那么概率树$t$的概率为所有规则概率的乘积
$$P(t) = \prod_{i} q(A_i \rightarrow \beta_i)$$
对于任意非终结符$A_i$,有$$\sum_{\beta} q(A_i \rightarrow \beta |A_i) = 1$$
下面是一个实例,便于理解

MLE:从训练数据中估计每个规则的概率
$$q_{ML}(A_i \rightarrow \beta) = \frac{count(A_i \rightarrow \beta)}{count(A_i)}$$
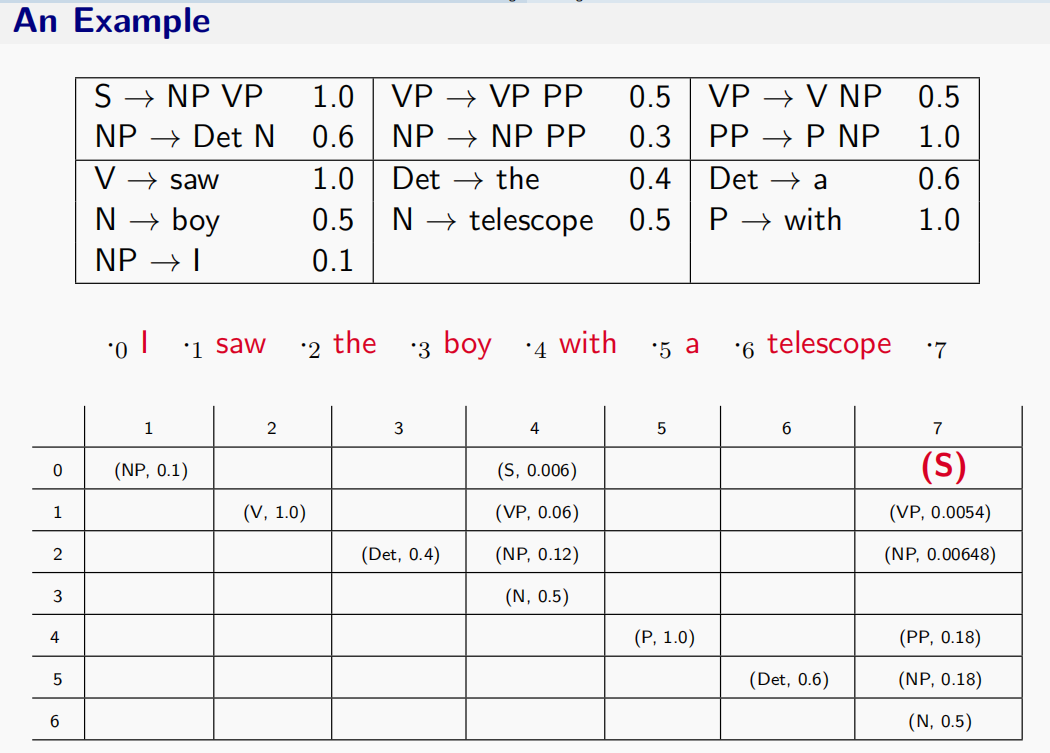
CKY解析算法
给出一个PCFG和句子$s$,定义$T(s)$为以$s$为输出结果的树的集合,我们想要找到$$\hat{t} = argmax_{t \in T(s)} P(t)$$
采用CKY算法进行动态规划
定义$\pi[i,j,X]$为从词序$i$到$j$生成非终结符$X$的最大概率
然后根据规则填充如下表格:
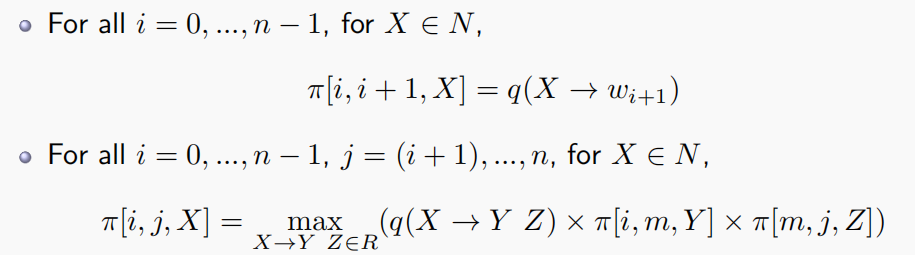
评估
使用标注精确率(Labeled Precision)、标注召回率(Labeled Recall)、F1值
常见做法:
在Penn Treebank上训练(02-21节),测试在23节上,词性标签序列上的F1通常在70%左右