句法分析 II
本文最后更新于 2026年6月14日 下午
北京大学信息科学技术学院 自然语言处理基础(2026春)的课程笔记
第十讲:Syntactic Analysis II
依存结构
依存关系
我认为语言最本质的特性,也是迄今为止发现的最令人费解的特性,就是所谓的“结构依赖性”。————诺姆·乔姆斯基

上面是一个例子,展示了词与词之间的依存关系
依存关系本质上是一种二元关系,其中一个是核心词(head),另一个是依存词(dependent)
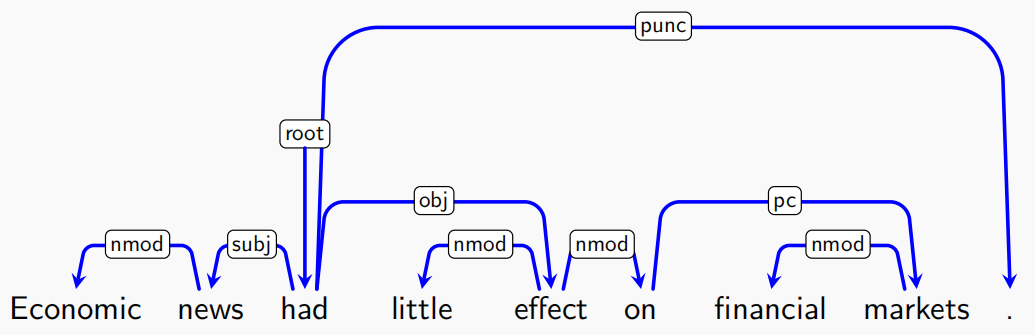
如上图,依存关系可以被表示为一条有向弧,从核心词指向依存词
Universal Dependencies(UD)项目定义了37种常见关系(如 nsubj, obj, iobj, det, case, conj 等)
依存图(树)
大部分情况下依存关系可以用树表示,但也有一些特殊情况,例如下面这个句子,所以为了满足一般性,我们还是用依存图来表示
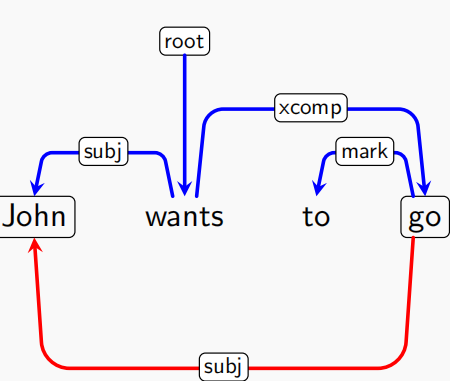
一个合法的依存图通常满足:
连通性:所有节点通过弧相连
无环性:不能有循环依赖
单头约束:每个词只能有一个核心词
投射性(projectivity):如果词 $i$ 是词 $j$ 的核心,则 $i$ 和 $j$ 之间的所有词都必须直接或间接从属于 $i$,即弧不能交叉
不过,大多数理论框架并不假设投射性,需要非投射性结构来解释长距离依赖关系及自由词序现象
依存结构和短语结构的对比

依存句法分析
花园小径句:语法正确,但是句子开头容易让人产生错觉
The old man the boat. 此处man为动词……
结构预测的两种方法
离散优化:定义评分函数并寻找得分最高的结构,如前面学过的viterbi,CKY算法等(dp)
增量搜索:搜索状态为当前构建的部分结构,每次操作逐步拓展结构,经常采用贪心,可以用beam search来提升性能
基于转移的依存解析框架
核心组件:
配置(configuration):包含栈(stack)、缓冲区(buffer)、已构建的弧集(A)。
初始:stack=[ROOT],buffer=[w1, w2, …, wn]
终止:stack=[ROOT],buffer为空
需要注意的是这里的缓冲区本质上也是栈结构,所以后续为了不产生歧义,我们统一用stack和buffer来描述两者
转移(transition):改变配置的动作
解析器:每次根据当前状态选择下一个动作,直到终止。
常用转移动作(Arc-standard 算法):
Shift:将buffer的第一个词压入stack
Left-Arc:buffer栈顶元素向stack栈顶元素连线,stack栈顶元素出栈,从此这个词消失
Right-Arc:stack栈顶元素向buffer栈顶元素连线,buffer栈顶元素出栈,从此这个词消失,然后stack栈顶元素出stack,进入buffer
下面是ppt中给出的一个实例,大家可以自行推导一遍,感觉这是本节课的重中之重,考试大概率会考()
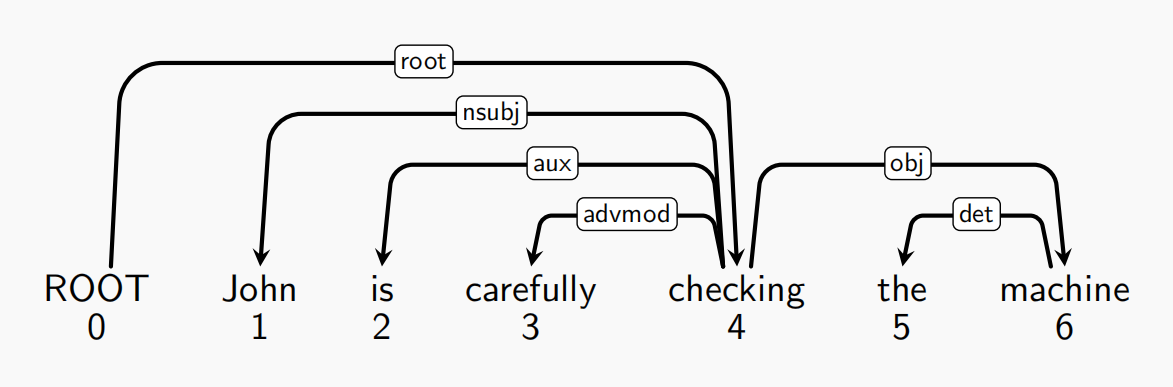

后续就是Right-Arc
stack顶是checking(4),buffer头部是machine(6),确立“checking(4)→ machine(6)”(obj,宾语),6消失4入buffer
stack:[0];buffer:[4];A:增加(4,6,obj)
stack顶是ROOT(0),buffer头部是checking(4),确立“ROOT(0)→ checking(4)”(root),4消失0入buffer
stack:ø;buffer:[0];A:增加(0,4,root)
最后把buffer中的ROOT(0)移到stack中,结束算法
解析器学习
训练:使用树库(如UD Treebanks),通过有监督学习训练一个分类器(感知机、对数线性模型、神经网络等)来预测每个状态下应该执行哪个动作
解码:贪心搜索(每次取最高概率的动作),也可用beam search提高准确率
评估指标
无标签依附分数(UAS):只判断每个词的核心词是否正确(忽略标签)
有标签依附分数(LAS):同时判断核心词和关系标签是否正确
通常以句子中正确依附的词的比例来报告