神经序列建模及其扩展
本文最后更新于 2026年6月14日 下午
北京大学信息科学技术学院 自然语言处理基础(2026春)的课程笔记
第八讲:Neural Sequence Modelling and Beyond
回顾RNN
RNN的基本结构
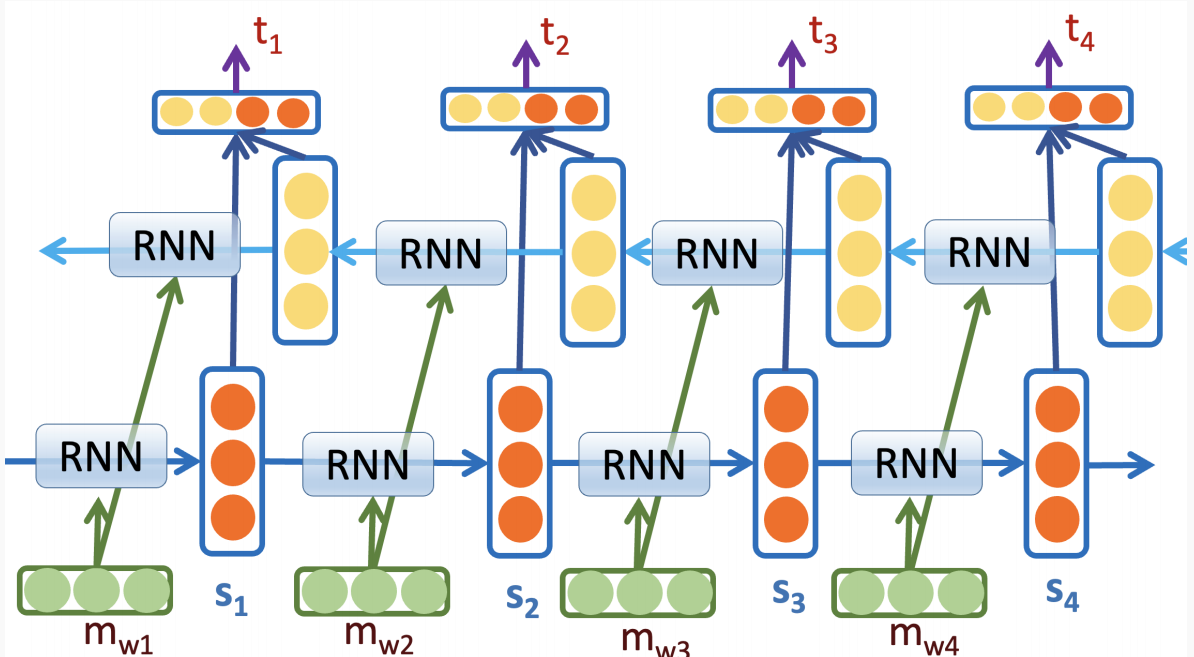
用于语言建模:用隐藏状态 $s_{t-1}$ 记忆历史信息 $w_1…w_{t-1}$
用于序列标注:每个位置输出一个标签(如 DET, ADJ, NOUN)
训练目标:最大化下一个词或标签的对数似然
问题:梯度消失/爆炸,难以捕捉长距离依赖
LSTM(长短期记忆网络)
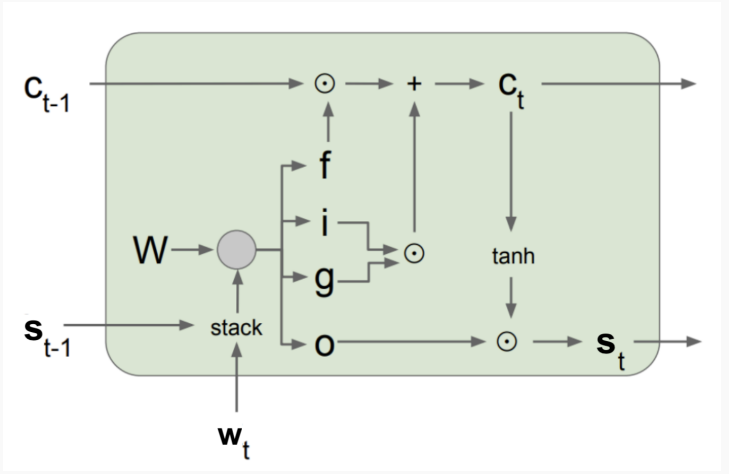
引入细胞状态 $c_t$ 作为长期记忆。
三个门:
输入门 $i_t$:决定写多少新信息。
遗忘门 $f_t$:决定擦除多少旧信息。
输出门 $o_t$:决定暴露多少记忆。
公式清晰,适合长序列建模。
GRU(门控循环单元)
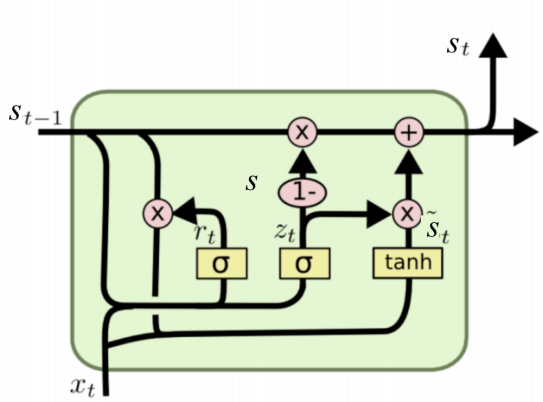
简化版LSTM,只有两个门:
重置门 $r_t$:决定忽略多少历史信息。
更新门 $z_t$:决定保留多少旧状态。
没有独立的细胞状态,计算更轻量。
二者对比
GRU训练更快
LSTM理论上更擅长捕捉长期依赖
LSTM具有对记忆内容的可控暴露特性,而GRU则不具备该特性
神经序列标注器
传统时代:
SOTA为条件随机场(Conditional Random Field, CRF)
有语言问题、不在词汇表的问题、标签偏差等
神经网络时代:
无需特征工程,没有语言障碍
有多种NN捕捉上下文信息,前向/反向传播
典型模型
BiLSTM + CRF(Lample et al., 2016)
Flair:上下文字符串嵌入
LUKE:基于Transformer的实体感知自注意力
FLERT:利用文档级特征提升NER性能
性能演进(CoNLL03)
从2016年之前的91.87%逐步提升到94%以上
近年主流模型大多基于Transformer(BERT、XLNet、PL-Marker等)
序列到序列学习 (seq2seq)
核心思想:
编码器(Encoder)将输入序列编码为固定向量 $v$
解码器(Decoder)基于 $v$ 和已生成的词逐步输出目标序列
典型工作:Sutskever et al., 2014
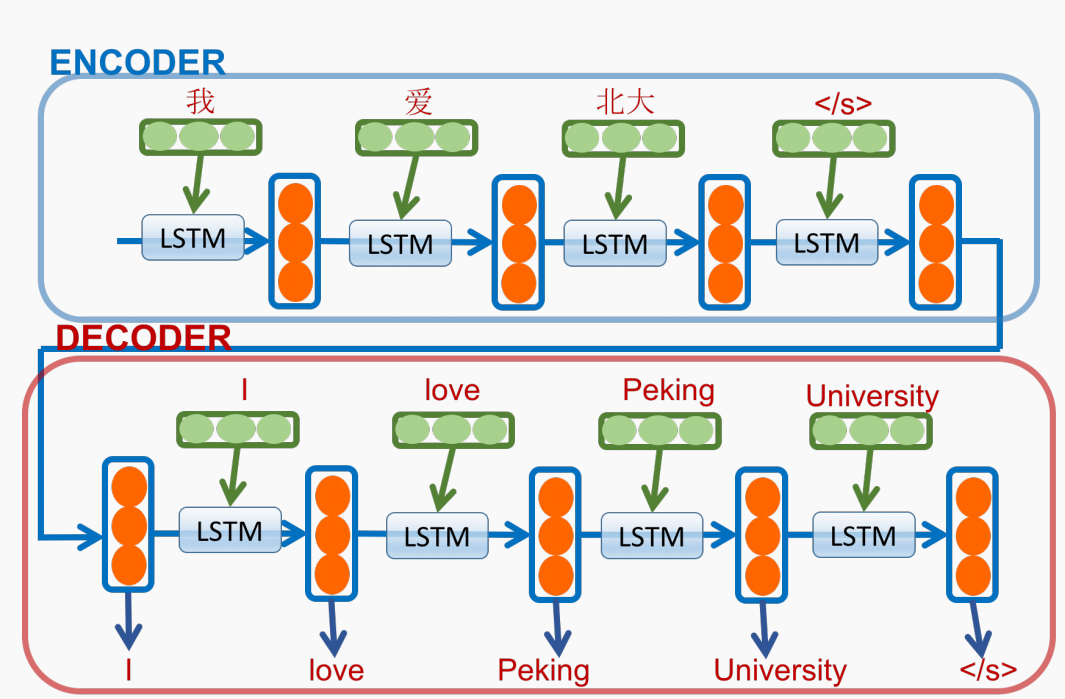
其中encoder将输入的句子映射为一个固定长度的向量
decoder则是一个以输入序列为条件的语言模型
LSTM学习长程时间依赖性
将机器翻译任务转换为seq2seq转换问题
给定输入序列$x_1,x_2,…,x_t$(例如英语句子)
目标是生成输出序列$y_1,y_2,…,y_{t’}$(例如对应的法语句子)
$p(y_1,y_2,…,y_{t’})=\Pi_{i=1}^{t’} p(y_i|y_1,…,y_{i-1},v)$
此处$v$是encoder通过LSTM将输入序列编码得到的固定向量
Sutskever等人还发现了:
更多参数通常会有更好的性能,采用双LSTM进行输入输出处理
深度网络优于浅层网络
输入反向处理优于原始处理
问题:固定向量 v 成为瓶颈,难以对齐长句子中的对应词(如“爱”和“love”)?
注意力机制(Attention)
这一部分就完全是老生常谈的Transformer了(终于讲到你啦!)
ai引论、生成模型基础乃至计算机视觉中都一再提到了,此处不再赘述
想要了解可以去看笔者的生成模型基础笔记,详细讲解了Transformer的结构和原理
一些trick:
自注意力机制、多头注意力、归一化点积、位置编码
层归一化、标签平滑、attn_mask、残差连接、dropout