序列标注 - 隐马尔可夫模型
本文最后更新于 2026年6月14日 下午
北京大学信息科学技术学院 自然语言处理基础(2026春)的课程笔记
第七讲:Sequence Tagging - Hidden Markov Models
序列标注
定义:给定一个由若干项组成的序列,为序列中的每一项赋予一个预定义标签的任务。
重要性:这是NLP中最基础的问题之一,它不再是孤立的单个决策,而是一连串相互影响的决策。
应用:
词性标注:为文本中每个单词标注词性
名词短语切分:切分出China Mobile这种名词短语
命名实体识别:识别出文本中的人名、地名、机构名等实体
(BIEO标记方案:Begin-Inside-Ending-Other)
词段划分:将字符序列分割为单词,适用于中文、日文等语言。
挑战:
词性歧义,比如 can 这个词在不同语境下词性大不相同
语义歧义,比如“南京市长江大桥”“下雨天留客天留我不留”不好断句()
词性标注
词可分为两类:开放词与封闭词
封闭词类:成员相对固定,通常是功能词,如介词、代词、冠词等
开放词类:成员会不断增长,主要是实义词,如名词、动词、形容词、副词等
标签集Tagset:用于细粒度词性标注的标准化代码
词性标注任务:给定训练集,需建立将句子映射至对应词性标注序列的函数。
训练数据包含词语序列及其词性标注序列。
形式化定义:输入为词语序列$x_1,x_2,…,x_n$,输出为对应的词性标注序列$y_1,y_2,…,y_n$
目标:找到一个函数,能够最大化给定词序列时标签序列的概率
$argmax_{y_1,y_2,…,y_n} P(y_1,y_2,…,y_n|x_1,x_2,…,x_n)$
根据贝叶斯公式,等价于最大化
$P(x_1,x_2,…,x_n|y_1,y_2,…,y_n)P(y_1,y_2,…,y_n)$
其中$P(y_1,y_2,…,y_n)$像是语言模型,可以用trigram,bigram这种估计
再对$x_i$和$y_i$做出条件独立假设,$P(x_1,x_2,…,x_n|y_1,y_2,…,y_n) \approx \prod_{i=1}^{n} P(x_i|y_i)$
隐马尔可夫模型(Hidden Markov Models)
状态:即我们想要预测的标签(如词性),是不可直接观测的“隐”状态
输出:即我们可以观测到的词
初始状态:句子的开始(START)
参数:
转移概率 $p(yₙ|yₙ₋₁)$:从一个标签转移到下一个标签的概率
发射概率 $p(xₙ | yₙ)$:在给定标签下,生成某个词的概率
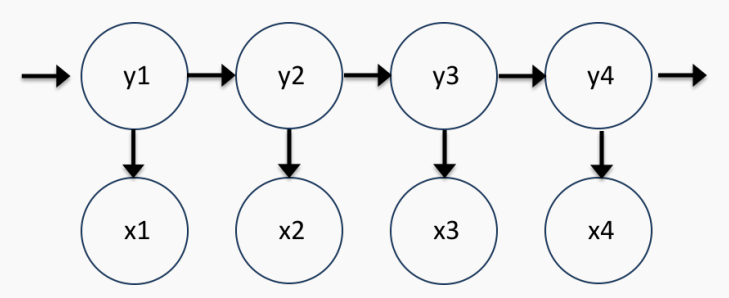
从初始状态开始,选择第一个状态(标签)$y₁$
根据第一个状态,发射(生成)第一个词$ x₁$
根据当前状态 $y₁$,转移到下一个状态 $y₂$
根据 $y₂$,发射第二个词 $x₂$
重复上述过程,直到生成整个句子
参数估计:与语言模型类似,极大似然估计+平滑
解码问题
有了一个训练好的HMM模型,给定一个新的句子,我们需要找出概率最高的标签序列
如果采用暴力搜索,对于一个长度为$ n $的句子,如果标签集大小为 $|S|$,那么可能的标签序列数量是 $|S|ⁿ$,这是指数级的,无法穷举
所以此处我们采用动态规划(维特比算法)
通过维护一个表格 $π(k, u, v)$ 来记录到第 $k $个词为止,以标签 $u $和 $v$ 结尾的所有可能标签序列中的最大概率
$\pi(k,u,v)=max_{y_{k-1}=u,y_k=v} \Pi_i^k p(y_i|y_{i-2},y_{i-1})\Pi_i^kp(x_i|y_i)$
算法步骤:
初始化:$π(0, START, START) = 1$
递推:遍历句子中的每个位置 $i$,以及可能的标签对 ($u, v)$,利用递推公式计算 $π(i, u, v)$,并记录下是哪个$ w $使得这个概率最大
终止:在句子的最后,选择能使 $π(n, u, v) * p(STOP|u, v)$ 最大的标签对 $(u, v) $作为最后两个词的标签
回溯:根据记录的回溯指针 $path(i, u, v)$,从最后一个标签对开始,逐步向前推演出整个最优标签序列
时间复杂度:$O(n * |S|^3)$,远优于指数级暴力搜索。如果使用一阶HMM(只依赖前一个标签),复杂度可降至 $O(n * |S|²)$
dp和贪心的折中:beam Search,比如$top16$,在生成模型基础中略有提到
dp相当于宽度无限的beam search,贪心相当于宽度为1的beam search
可以加经验,采用重排序(re-ranking)的方式,先用beam search得到前$k$个候选标签序列,再用一个更复杂的模型(如神经网络)对这$k$个候选进行重新评分,选择得分最高的作为最终输出
总结
HMM的优点
模型简洁,有清晰的数学公式
参数估计简单直接(基于计数)
解码算法(维特比)优雅高效
HMM的局限性
需要大量的高质量标注数据
模型假设(马尔可夫假设)可能过于简化,不能灵活地引入复杂的特征(如词的拼写、大小写、前后缀等)
无法“学习”特征,所有知识都来源于共现计数