分布语义学
本文最后更新于 2026年6月14日 下午
北京大学信息科学技术学院 自然语言处理基础(2026春)的课程笔记
第六讲:Distributional Semantics
词义问题
传统方法
WordNet 是一个大型英语词汇数据库,它将名词、动词、形容词和副词组织成同义词集合(synset),每个synset代表一个不同的概念。
以 bank 为例:
Synset 1(河岸):sloping land beside a body of water
Synset 2(金融机构):depository financial institution
每个词可能有多个词义(sense),WordNet 显式地编码了这些信息
词之间:同义词、反义词、相似词、相关词、褒义贬义词
评估数据集
WordSim353:用于评估词相似度(Similarity)和相关度(Relatedness)的数据集
相似度:如 tiger - cat (7.35),侧重“同类”。
相关度:如 computer - keyboard (7.62),侧重“共现”。
SimLex-999:另一个数据集,更关注相似度而非相关度
(如 vanish - disappear 得分9.8,而 hole - agreement 得分0.3)
语义场(Semantic Field):指某个特定语义域中的一组词,如医院相关的(surgeon, scalpel, nurse),餐厅相关的(waiter, menu, plate)
词汇表示
朴素表示:将每个词视为原子,用独热向量表示
例如:$[0,0,…,1,0,…,0]$
向量的维度等于词汇表大小(可能达到5万甚至1300万)
问题:占用空间大,表述稀疏
基于特征的POS标注器:
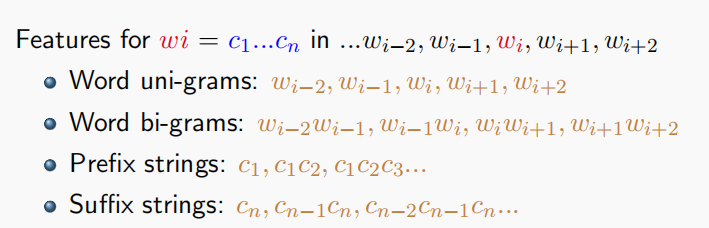
如上,从unigram bigram 前缀 后缀四个方面来提取特征
发现低频词的准确率较低,具有挑战性
分布语义学
经典问题:buffalo的一词多义
Buffalo buffalo Buffalo buffalo buffalo buffalo Buffalo buffalo.这是一个完整的句子()
同义词问题:adept, expert, good, practiced, proficient, skillful
全新词汇问题:tezguino这种语言学家胡编乱造的词
核心理念:分布假说
一个直觉:可以通过上下文判断词义!
(无聊的定义:分布语义学是一套基于语言使用语境来表征词义的技术体系。)
一阶共现:词与词在文本中邻近出现,如 wrote 和 book
二阶共现:词与词有相似的邻居,如 wrote 和 said 都常与某人说话或写作相关
向量空间模型
核心思想:将词嵌入到一个低维的实数向量空间中,避免出现独热向量那种维度极高的情况
这类模型通常被称为嵌入模型或向量空间模型(VSM)
也就是老生常谈的word embeddings
如何构建:
定义上下文:例如,取目标词左右各 $w$ 个词作为上下文。
构建共现矩阵:行是目标词,列是上下文词,值为共现次数。
例如,语料库中有句子:
… and the cute kitten purred and then …
… the cute furry cat purred and miaowed …
… that the small kitten miaowed and she …
基于此,可以构建出 kitten 和 cat 的稀疏向量,如:
$kitten = [0, 1, 0, 0, 1, 1, 0, 1]$ (对应上下文词: bit, cute, furry, loud, miaowed, purred, …)
$cat = [0, 1, 1, 0, 1, 0, 0, 0]$
$dog = [1, 0, 1, 1, 0, 0, 1, 0]$
其中the, that, and, …这种词称为停用词,不计入向量中
当然也需要考虑词汇的变形,比如miaow和miaowed,dog和dogs
窗口大小w的值取决于你的目标:
较短窗口对应更多句法表示,较长窗口对应更多语义表示。
权重:点互信息(PMI)
问题:原始共现次数受高频词(如 the, and)影响,无法准确衡量词之间的关联强度
所以我们引入Pointwise mutual information(PMI),即为ai引论中讲过的互信息
$PMI(X,Y)=log\frac{P(x,y)}{P(x)P(y)}$
计算两个事件(词 x 和上下文 y)共现的概率是否高于随机独立共现的概率
PPMI:将负的PMI值设为0,只保留正相关。
作用:可以凸显出与特定词有强关联的上下文词。例如,apricot 如果只与 sugar 共现,其PMI值就会很高。
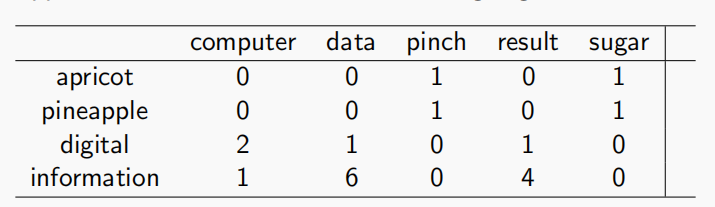
上面是一个例子
$PPMI(apricot,sugar)=log_2\frac{1×19}{2×2}$
PMI算法存在对罕见事件的偏差问题,极少数词汇的PMI值会异常偏高。
解决方案:采用拉普拉斯平滑法(加一法)处理数据
相似度计算
余弦相似度:测量两个向量之间的夹角
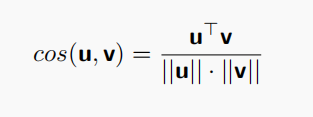
夹角越小,余弦值越接近1,表示词越相似
该指标忽略了向量的长度(即词频),只关注方向(即词的分布模式)
使用句法定义词的上下文(Zellig Harris,1968)
若两个词具有相似的句法语境,即定义为相似词,例如duty和responsibility
对于文档?我们建立文档矩阵
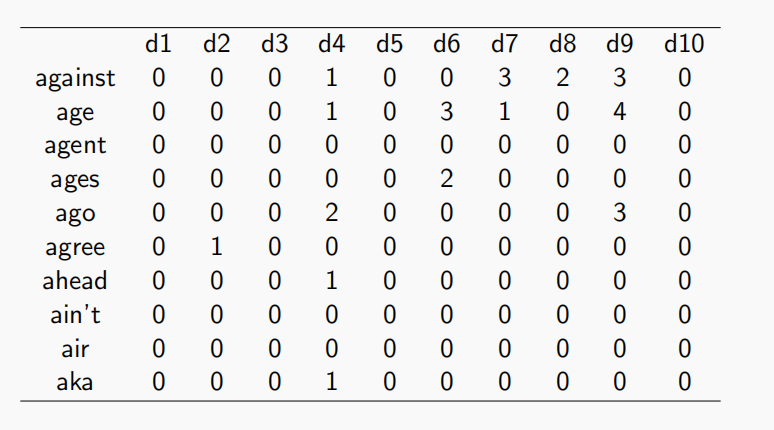
然而该矩阵似乎并不友好,更方便的还是TF-IDF(详见之前的笔记)
降维
降维的目的在于防止稀疏,PPMI向量仍然是高维且稀疏的
目标就是获得低维稠密的向量
潜在语义分析(LSA):
对词-文档矩阵$A$进行奇异值分解
$A=M × Diag(s) × C^{T}$
这样一来保留了最大的$k$个奇异值,得到低维词向量$M$
概率潜在语义分析(PLSA):
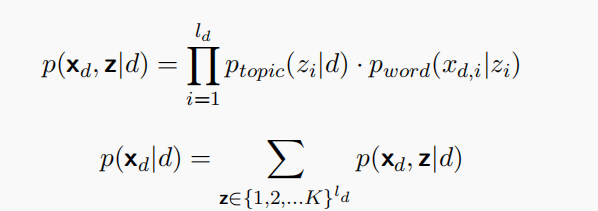
引入主题作为隐变量,每篇文档$d$由$K$个主题混合而成
但是PLSA 无法为训练数据之外的文本分配概率
神经网络
词嵌入(Word Embeddings):词被表示为低维、稠密的实数向量,如 $[0.456, 0.193, 5.391, …]$
Word2Vec:一个代表性的预测模型,有两种结构
连续词袋模型(CBOW):用上下文词预测中心词,$p(word|context)$

Skip-gram:用中心词预测上下文词,$p(context|word)$
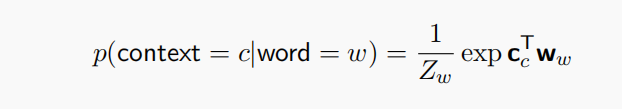
每个词对应两个向量,当词为目标词使用$w$,词为上下文使用$c$
优势:相比基于计数的方法,预测模型能更好地捕捉复杂的语义关系,并在下游任务中表现更好。
内部评估(Intrinsic):直接测试词向量的相似度与人类判断的相关性,或进行类比推理测试(如“北京之于中国 相当于 巴黎之于?”)。
外部评估(Extrinsic):将词向量作为特征输入到下游NLP任务(如分类器)中,观察任务性能是否提升。
上下文表示
静态的word embedding无法解决一词多义问题
所以我们需要上下文表示,即语境化词嵌入(Contextualized Word Embeddings)